pandas duplicate drop시 중복된 값을 평균 만들기
# DataFrame 생성
|
1
2
3
4
|
df = pd.DataFrame({
'kind': ['bus', 'bus', 'cake', 'bus', 'taxi', 'taxi'],
'cnt': [1, 2, 3, 4, 3, 9]
})
|
cs |

# duplicate drop 시 중복된 값을 평균 만들기
1) duplicate drop을 하는 경우에 바로 함수에서 제공하면 좋을 것 같지만 없는 것 같음.
2) 간단한 코드를 구현하여 해결함.
(1) 먼저 중복되는 값들 확인.
(2) 평균 값을 계산하여 해당 DataFrame 맨 뒤에 붙임.
(3) pd.drop_duplicates 함수를 통해 맨 마지막 값만 남기고 나머지는 지움.
3) 해당 코드
|
1
2
3
4
5
|
duplicate_list = df.duplicated(subset=['kind'], keep=False)
for d in df[duplicate_list]['kind'].unique():
mean_value = np.mean(df[df['kind'] == d]['cnt'].tolist())
new_data = pd.DataFrame({'kind': d, 'cnt': mean_value}, index=[0])
df = pd.concat([df, new_data])
|
cs |

https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.duplicated.html
pandas.DataFrame.duplicated — pandas 1.5.3 documentation
Only consider certain columns for identifying duplicates, by default use all of the columns.
pandas.pydata.org
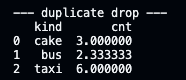
4) 중복된 값 제거 코드
|
1
|
df.drop_duplicates(subset='kind', keep='last', inplace=True, ignore_index=True)
|
cs |
- columns은 'kind'로 설정 (subset='kind')
- 마지막 값만 남도록 설정 (keep='last')
- 현재 DataFrame에 덮어쓰기 (inplace=True)
- 현재 index를 무시하고 0 ~ n-1으로 변경 (ignore_index=True)
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
pandas.DataFrame.drop_duplicates — pandas 1.5.3 documentation
next pandas.DataFrame.droplevel
pandas.pydata.org